Mengenal Sekilas Large Languge Models (LLMs)
Oleh: Ahmad Fathan Hidayatullah, S.T., M.Cs., Ph.D.
Dalam kurun lima tahun belakangan, Large Language Models (LLMs) telah menjadi sorotan utama dalam perkembangan teknologi kecerdasan buatan. Keberadaannya mendorong perubahan besar dalam cara manusia berinteraksi dengan mesin. Interaksi manusia dengan mesin kini tidak lagi terbatas pada perintah sederhana, tetapi sudah menyerupai percakapan layaknya komunikasi sehari-hari. LLMs merupakan salah satu inovasi paling signifikan dalam pengembangan AI (Artificial Intelligence), khususnya dalam bidang natural language processing (NLP). Model ini memungkinkan mesin untuk memahami, mengolah, dan menghasilkan bahasa manusia dengan tingkat kecanggihan yang belum pernah terjadi sebelumnya.
Apa Itu Large Language Models?
Large Language Models (LLMs) merupakan suatu model bahasa yang digunakan sebagai foundation models yang dirancang untuk dapat memahami dan menghasilkan bahasa manusia secara alami. Model ini dilatih menggunakan kumpulan data teks dalam skala besar. Data teks yang digunakan berasal dari miliaran kata yang diperoleh dari berbagai sumber seperti artikel berita, buku, forum daring, dokumen akademik, dan percakapan sehari-hari.
Berbeda dengan pendekatan tradisional yang membutuhkan data berlabel, LLMs menggunakan metode self-supervised learning, yaitu teknik pelatihan di mana model belajar secara mandiri mengenali pola bahasa tanpa perlu pelabelan atau anotasi secara manual. Proses pelatihan ini memungkinkan model memahami struktur, makna, dan konteks bahasa secara menyeluruh.
Mengapa Disebut “Large”?
Secara umum, istilah “large” dalam LLMs tidak hanya merujuk pada ukuran model, tetapi juga mencerminkan kompleksitas dan cakupan data yang menjadi fondasi kemampuannya. Istilah “large” dalam LLMs merujuk pada dua aspek utama, yaitu jumlah parameter yang sangat besar dan volume data pelatihan yang masif. Parameter merupakan komponen internal yang dipelajari oleh model selama proses pelatihan untuk mengenali pola-pola dalam bahasa. Semakin besar jumlah parameter, semakin besar pula kapasitas model dalam menyimpan informasi dan menghasilkan keluaran yang kontekstual serta akurat.
Selain itu, istilah “large” juga menggambarkan skala data pelatihan yang digunakan. LLMs dilatih menggunakan miliaran hingga triliunan token1Unit terkecil dalam teks yang dianggap bermakna secara semantik. Token dapat berupa kata, frasa, atau simbol. yang dikumpulkan dari berbagai sumber, seperti artikel berita, buku, forum daring, hingga kode pemrograman. Pelatihan dengan volume data sebesar ini memungkinkan model memahami ragam bahasa, gaya penulisan, dan konteks yang luas dalam komunikasi manusia.
Tabel 1 memperlihatkan lima model LLM seperti GPT-3 [1], BLOOM [2], LLaMA 2 [3], PaLM 2 [4], dan DeepSeek-V2 [5]. Dari tabel tersebut, dapat kita lihat variasi dalam jumlah parameter dan ukuran data latih yang digunakan dari masing-masing model LLM.
Tabel 1. Contoh model LLM dengan jumlah parameter dan ukuran data latihnya.
| Model | Jumlah Parameter | Ukuran Data Latih |
| GPT-3 | 175 miliar | 500 miliar token |
| BLOOM | 176 miliar | 366 miliar token |
| LLaMA 2-65B | 65 miliar | 1,4 triliun token |
| PaLM 2 | 340 miliar | 3,6 triliun token |
| DeepSeek-V2 | 236 miliar | 8,1 triliun token |
Apa yang Dapat Dilakukan LLMs?
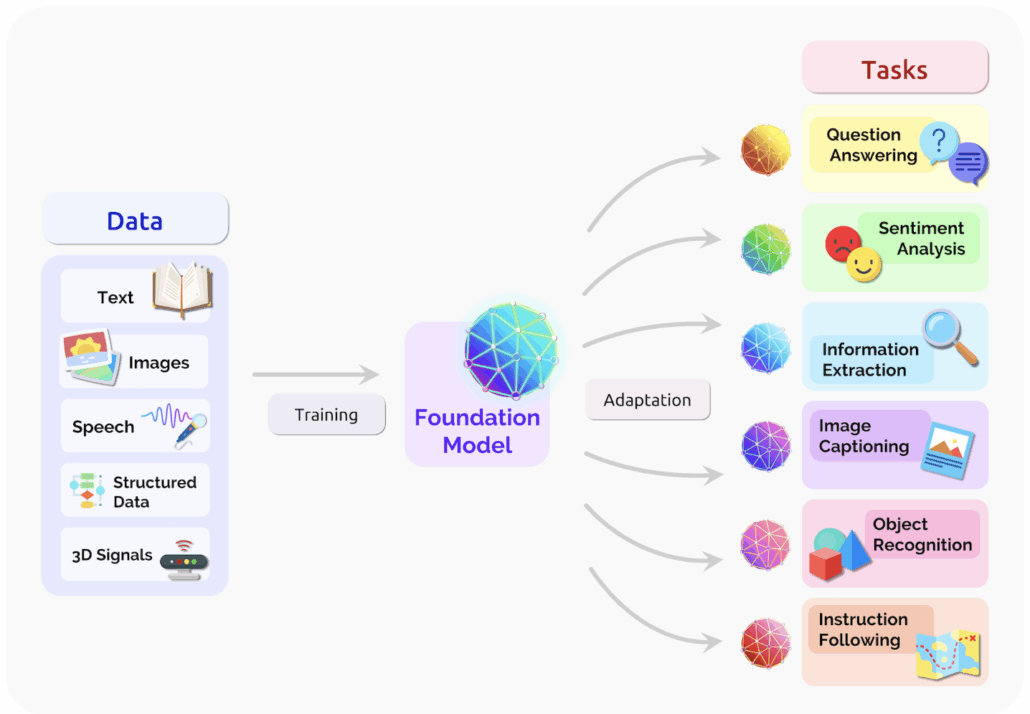
Kemampuan LLMs tidak hanya terbatas pada pemrosesan teks, tetapi juga mencakup berbagai jenis data dan tugas lanjutan. Sebagai foundation models, LLMs dilatih menggunakan beragam sumber data seperti teks, gambar, suara, data terstruktur, hingga sinyal 3D. Setelah melalui proses pelatihan, model ini dapat disesuaikan (adapted) untuk menyelesaikan berbagai tugas seperti menjawab pertanyaan (question answering), analisis sentimen, ekstraksi informasi, penjelasan gambar (image captioning), pengenalan objek, hingga mengikuti instruksi.
Yang membuat LLMs istimewa adalah fleksibilitasnya dalam menangani beragam kebutuhan NLP hanya dengan satu model. Saat ini, satu sistem berbasis LLMs dapat digunakan untuk menerjemahkan teks, merangkum dokumen, menghasilkan tulisan otomatis, dan berbagai tugas lainnya. Karena kemampuannya yang serbaguna dan mudah diadaptasi, LLMs disebut sebagai general-purpose models yang dapat diterapkan di berbagai domain, mulai dari pendidikan, bisnis, layanan publik, hingga riset ilmiah.
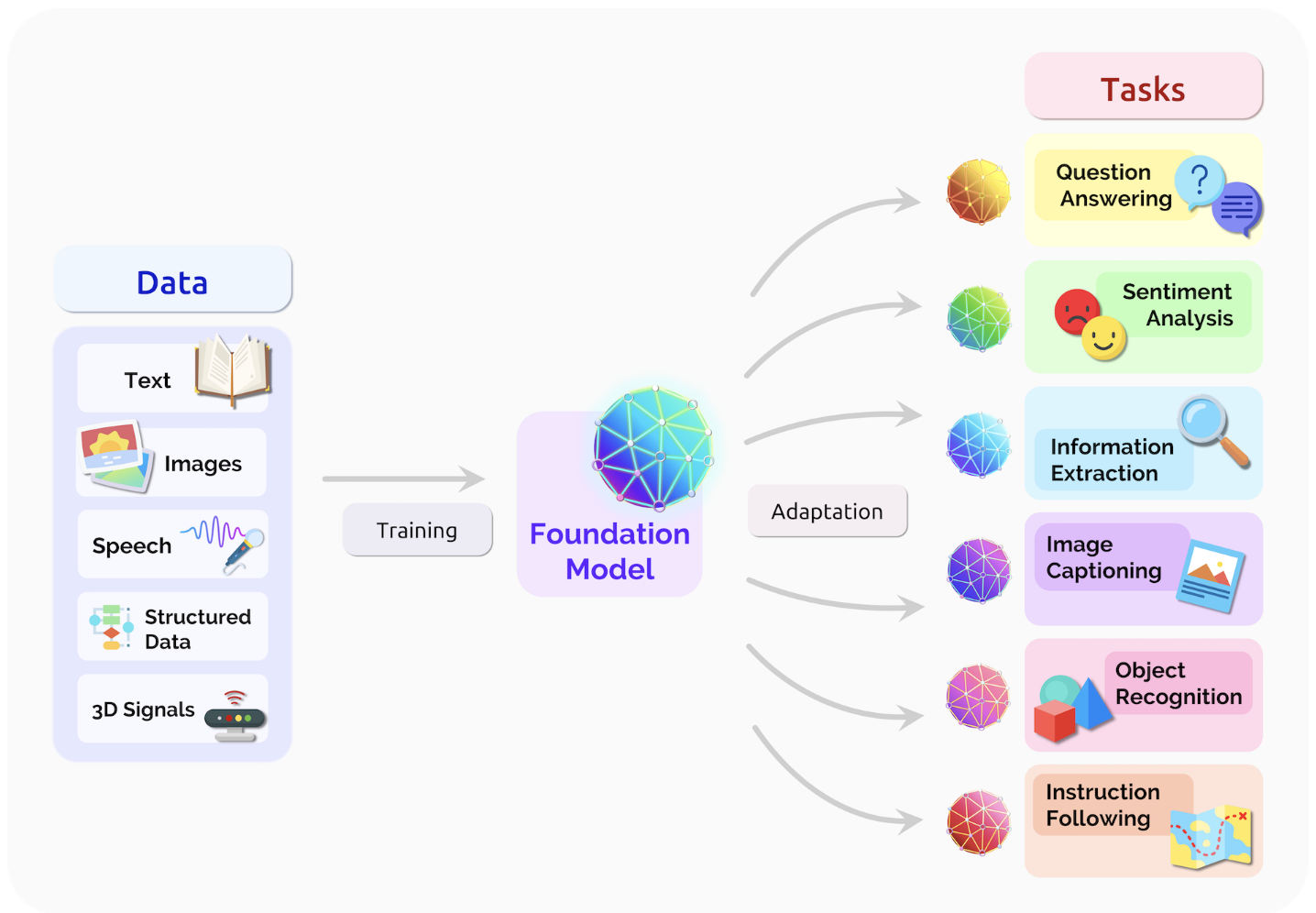
Gambar 1. Ilustrasi LLMs sebagai foundation model yang dapat menggabungkan informasi dari berbagai jenis data dan diadaptasi untuk berbagai tugas lanjutan [6].
Milestones Teknologi LLMs (2017–2025)
Perkembangan LLMs berlangsung sangat pesat dalam beberapa tahun terakhir. Hal ini tidak terlepas dari kemajuan teknologi model arsitektur deep learning yang terus berkembang. Selain itu, perkembangan LLMs juga didukung oleh kemunculan konsep attention mechanism yang diadopsi dalam model Transformer serta peningkatan daya komputasi yang memungkinkan pelatihan model dalam skala yang jauh lebih besar. Ketersediaan data dalam jumlah besar dan dukungan dari komunitas open-source turut mempercepat adopsi dan inovasi dalam pengembangan LLMs.
Seiring waktu, LLMs terus berkembang, semakin cerdas, efisien, dan mudah diakses. Evolusi ini ditandai dengan sejumlah tonggak penting yang merefleksikan lompatan kemampuan teknologi dan dampaknya terhadap penggunaan di dunia nyata. Gambar 2 menjelaskan beberapa tonggak penting dalam evolusi LLMs yang meliputi:
2017 – Transformer
Arsitektur Transformer yang diperkenalkan oleh Vaswani dkk. [7] menjadi landasan utama LLMs. Model ini memperkenalkan mekanisme self-attention yang memungkinkan pemrosesan hubungan antarkata dalam satu kalimat secara efisien, tanpa bergantung pada urutan kata secara berurutan seperti pada arsitektur LSTM (Long Short-Term Memory).
2020 – GPT-3
Pada tahun 2020, OpenAI merilis model yang disebut dengan Generative Pre-trained Transformer 3 (GPT-3). Model ini dilatih dengan 175 miliar parameter, yang menunjukkan kemampuan luar biasa dalam menghasilkan teks yang koheren dan kontekstual, termasuk menjawab pertanyaan, menulis esai, dan menyusun puisi.
2022 – ChatGPT
Kemunculan ChatGPT pada tahun 2022 menjadi titik balik dalam meluasnya adopsi LLM oleh masyarakat umum. ChatGPT dengan cepat dimanfaatkan dalam berbagai bidang, mulai dari edukasi sebagai asisten belajar, hiburan interaktif, hingga produktivitas kerja seperti menyusun email, merangkum dokumen, dan menulis kode program.
2025 – DeepSeek-R1
DeepSeek mewakili generasi baru LLMs open-source yang dirancang untuk mendemokratisasi akses terhadap teknologi AI. Dengan menyediakan model yang dapat diakses bebas oleh peneliti maupun pengembang tanpa hambatan legal atau biaya tinggi, DeepSeek mendorong adopsi yang lebih luas. Selain terbuka, model ini juga menawarkan kecerdasan tinggi, kecepatan pemrosesan yang efisien, dan biaya operasional yang rendah, menjadikannya solusi AI yang inklusif dan mudah diterapkan di berbagai sektor.
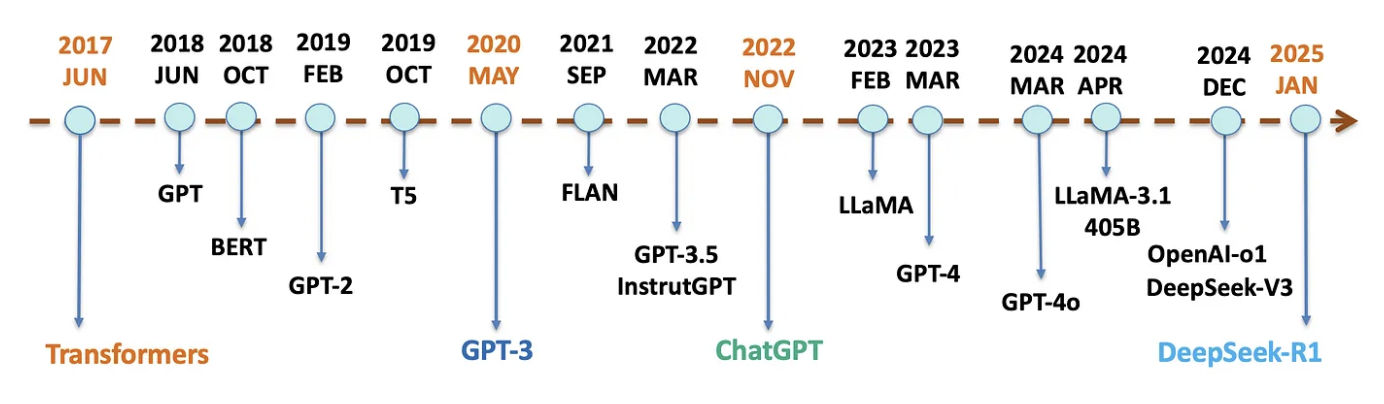
Gambar 2. Milestones Teknologi LLMs (2017-2025) [8]
Penutup
Sebagai penutup, kemunculan LLMs telah menjadi salah satu pilar utama dalam perkembangan teknologi kecerdasan buatan. LLMs memberikan peluang baru dalam pemrosesan bahasa, pemahaman konteks, dan interaksi manusia dengan mesin. Kemampuan LLMs yang fleksibel, skalabel, dan adaptif membuatnya dapat diterapkan di berbagai bidang. Dengan terus berkembangnya teknologi dan terbukanya akses melalui model-model open-source seperti DeepSeek, masa depan LLMs menjanjikan ekosistem AI yang lebih inklusif, kolaboratif, dan berdampak luas bagi masyarakat luas.
Referensi
[1] T. Brown et al., “Language models are few-shot learners,” Adv Neural Inf Process Syst, vol. 33, pp. 1877–1901, 2020.
[2] T. Le Scao et al., “Bloom: A 176b-parameter open-access multilingual language model,” 2023.
[3] H. Touvron et al., “Llama 2: Open foundation and fine-tuned chat models,” arXiv preprint arXiv:2307.09288, 2023.
[4] R. Anil et al., “Palm 2 technical report,” arXiv preprint arXiv:2305.10403, 2023.
[5] A. Liu et al., “Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model,” arXiv preprint arXiv:2405.04434, 2024.
[6] R. Bommasani et al., “On the opportunities and risks of foundation models,” arXiv preprint arXiv:2108.07258, 2021.
[7] A. Vaswani et al., “Attention Is All You Need,” in arXiv:1706.03762 [cs], Long Beach, CA, USA, Dec. 2017. [Online]. Available: http://arxiv.org/abs/1706.03762
[8] LM Po, “A Brief History of LLMs From Transformers (2017) to DeepSeek-R1 (2025).” Accessed: May 06, 2025. [Online]. Available: https://medium.com/@lmpo/a-brief-history-of-lmms-from-transformers-2017-to-deepseek-r1-2025-dae75dd3f59a

 DALL-E
DALL-E